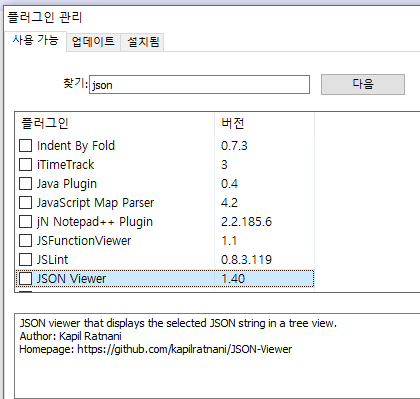
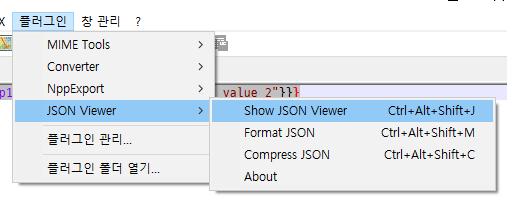
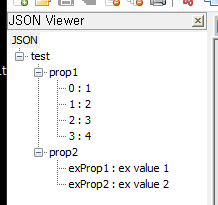
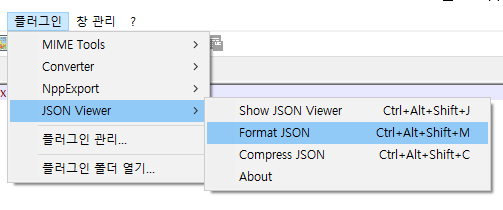
년/월/일/시 형태의 디렉토리에 로그를 보관하고 있는데 2022-05-31 13:00:00 ~ 2022-06-01 01:00:00 사이의 로그를 추출하고 싶을 때 난감하다.
# date --help
Usage: date [OPTION]... [+FORMAT]
or: date [-u|--utc|--universal] [MMDDhhmm[[CC]YY][.ss]]
Display the current time in the given FORMAT, or set the system date.
Mandatory arguments to long options are mandatory for short options too.
-d, --date=STRING display time described by STRING, not 'now'
--debug annotate the parsed date,
and warn about questionable usage to stderr
-f, --file=DATEFILE like --date; once for each line of DATEFILE
-I[FMT], --iso-8601[=FMT] output date/time in ISO 8601 format.
FMT='date' for date only (the default),
'hours', 'minutes', 'seconds', or 'ns'
for date and time to the indicated precision.
Example: 2006-08-14T02:34:56-06:00
-R, --rfc-email output date and time in RFC 5322 format.
Example: Mon, 14 Aug 2006 02:34:56 -0600
--rfc-3339=FMT output date/time in RFC 3339 format.
FMT='date', 'seconds', or 'ns'
for date and time to the indicated precision.
Example: 2006-08-14 02:34:56-06:00
-r, --reference=FILE display the last modification time of FILE
-s, --set=STRING set time described by STRING
-u, --utc, --universal print or set Coordinated Universal Time (UTC)
--help display this help and exit
--version output version information and exit
FORMAT controls the output. Interpreted sequences are:
%% a literal %
%a locale's abbreviated weekday name (e.g., Sun)
%A locale's full weekday name (e.g., Sunday)
%b locale's abbreviated month name (e.g., Jan)
%B locale's full month name (e.g., January)
%c locale's date and time (e.g., Thu Mar 3 23:05:25 2005)
%C century; like %Y, except omit last two digits (e.g., 20)
%d day of month (e.g., 01)
%D date; same as %m/%d/%y
%e day of month, space padded; same as %_d
%F full date; same as %Y-%m-%d
%g last two digits of year of ISO week number (see %G)
%G year of ISO week number (see %V); normally useful only with %V
%h same as %b
%H hour (00..23)
%I hour (01..12)
%j day of year (001..366)
%k hour, space padded ( 0..23); same as %_H
%l hour, space padded ( 1..12); same as %_I
%m month (01..12)
%M minute (00..59)
%n a newline
%N nanoseconds (000000000..999999999)
%p locale's equivalent of either AM or PM; blank if not known
%P like %p, but lower case
%q quarter of year (1..4)
%r locale's 12-hour clock time (e.g., 11:11:04 PM)
%R 24-hour hour and minute; same as %H:%M
%s seconds since 1970-01-01 00:00:00 UTC
%S second (00..60)
%t a tab
%T time; same as %H:%M:%S
%u day of week (1..7); 1 is Monday
%U week number of year, with Sunday as first day of week (00..53)
%V ISO week number, with Monday as first day of week (01..53)
%w day of week (0..6); 0 is Sunday
%W week number of year, with Monday as first day of week (00..53)
%x locale's date representation (e.g., 12/31/99)
%X locale's time representation (e.g., 23:13:48)
%y last two digits of year (00..99)
%Y year
%z +hhmm numeric time zone (e.g., -0400)
%:z +hh:mm numeric time zone (e.g., -04:00)
%::z +hh:mm:ss numeric time zone (e.g., -04:00:00)
%:::z numeric time zone with : to necessary precision (e.g., -04, +05:30)
%Z alphabetic time zone abbreviation (e.g., EDT)
By default, date pads numeric fields with zeroes.
The following optional flags may follow '%':
- (hyphen) do not pad the field
_ (underscore) pad with spaces
0 (zero) pad with zeros
^ use upper case if possible
# use opposite case if possible
After any flags comes an optional field width, as a decimal number;
then an optional modifier, which is either
E to use the locale's alternate representations if available, or
O to use the locale's alternate numeric symbols if available.
Examples:
Convert seconds since the epoch (1970-01-01 UTC) to a date
$ date --date='@2147483647'
Show the time on the west coast of the US (use tzselect(1) to find TZ)
$ TZ='America/Los_Angeles' date
Show the local time for 9AM next Friday on the west coast of the US
$ date --date='TZ="America/Los_Angeles" 09:00 next Fri'
GNU coreutils online help: <https://www.gnu.org/software/coreutils/>
Report date translation bugs to <https://translationproject.org/team/>
Full documentation at: <https://www.gnu.org/software/coreutils/date>
or available locally via: info '(coreutils) date invocation'
date 명령을 이용하면 비슷하게 흉내낼 수 있다.
# date -d "2022-05-31 13:00:00" +"%s"
1653969600
-d 옵션을 사용해 문자열 형태의 datetime 을 받아서 %s 형식을 사용해 unix time( 1970-01-01 00:00:00 utc 부터 지난 시간(초) ) 를 가져올 수 있다.
for /f 명령어로 라인 단위 처리할 때 # 같은 문자열로 시작하는 라인을 무시하고 싶을 때 첫번째 문자열을 비교해서 처리했는데 기본 제공되는 옵션이 있었다.
FOR /F ["옵션"] %변수 IN (파일-집합) DO 명령 [명령-매개 변수]
FOR /F ["옵션"] %변수 IN ("문자열") DO 명령어 [명령-매개 변수]
FOR /F ["옵션"] %변수 IN ('명령어') DO 명령어 [명령-매개 변수]
또는 usebackq 옵션이 있는 경우:
FOR /F ["옵션"] %변수 IN (파일-집합) DO 명령 [명령-매개 변수]
FOR /F ["옵션"] %변수 IN ('문자열') DO 명령어 [명령-매개 변수]
FOR /F ["옵션"] %변수 IN (`명령어`) DO 명령어 [명령-매개 변수]
파일-집합은 하나 이상의 파일 이름입니다. 파일-집합의 각 파일은
다음 파일로 이동하기 전에 열기 또는 읽기 등의 작업이 진행됩니다.
파일을 읽어서 문자열을 한 행씩 분리하고 각 행을 0개 이상의
토큰으로 구문 분석하는 과정으로 되어 있습니다. For 루프의 본문은
발견된 토큰 문자열에 설정된 변수 값(들)과 함께 호출됩니다.
기본값으로 /F는 파일의 각 행으로부터 분리된 토큰을 첫 번째 공백에
전달합니다. 빈 행은 건너뜁니다. "옵션" 매개 변수를 지정하여
기본 구문 분석 동작을 무시할 수 있습니다. 이것은 다른 구문 분석
매개 변수를 지정하는 하나 이상의 키워드를 갖는 인용 부호로
묶인 문자열입니다.
키워드는 아래와 같습니다.
eol=c - 행 끝 설명 문자를 지정합니다
(하나만)
skip=n - 파일의 시작 부분에서 무시할 행의 개수를
지정합니다.
delims=xxx - 구분 문자 집합을 지정합니다. 이것은 공백 또는
탭에 대한 기본 구분 문자 집합을 바꿉니다.
tokens=x,y,m-n - 각 줄에서 어떤 토큰이 각 반복에 대한
For 구문으로 전달될지를 지정합니다.
이 작업은 추가 변수 이름이 할당되도록 됩니다.
m-n 형식은 m에서부터 n까지를 나타냅니다.
토큰=문자열 내에 있는 마지막 문자가 별표(*)이면,
추가 변수가 할당되고, 분석된 마지막 토큰
뒤에 남아 있는 텍스트를 받습니다.
usebackq - 억음 악센트 기호(`) 내의 문자열을 명령으로
처리하며, 작은따옴표(')는 문자열 명령어로
큰따옴표(")는 파일-집합에서 파일 이름을
나타내도록 사용합니다.
다음 예제를 참고하십시오.
FOR /F "eol=; tokens=2,3* delims=, " %i in (myfile.txt) do @echo %i %j %k
위의 예제에서는 myfile.txt의 모든 행을 구문 분석하지만
세미콜론으로 시작하는 행은 무시하고, 각 행의 두 번째와
세 번째 토큰을 쉼표 및/또는 공백으로 구분되는 토큰으로
For 본문으로 전달합니다. 두 번째, 세 번째, 나머지 토큰을
가져오려면, For 본문 내용의 %i, %j, %k를 참조하십시오.
공백을 포함한 파일 이름의 경우, 파일 이름에 큰따옴표(")를
적용하십시오. 큰따옴표를 적용하려면 "usebackq" 옵션을
사용해야 합니다. 그렇지 않으면, 큰따옴표는 분석할 문자로
취급됩니다.
for 도움말 중에 eol 이라는 옵션을 사용하면 된다.
D:\test\work\test>type list.txt
line1
#line2
line3
D:\test\work\test>for /f %i in (list.txt) do @echo %i
line1
#line2
line3
옵션 없이 사용하면 각 라인별로 명령어를 실행한다.
D:\test\work\test>for /f "eol=#" %i in (list.txt) do @echo %i
line1
line3
윈도우즈 배치 파일 변수에서 하위 문자열을 가져오고 싶을 때는 %변수명:~시작위치,길이% 와 같은 형식을 사용한다.
c:\> help set
...
%PATH:~10,5%
은(는) PATH 환경 변수를 확장한 다음 확장된 결과의 11(10 오프세트)번째
문자에서 시작한 5 문자만 사용합니다. 길이를 지정하지 않으면 기본값을
변수 값의 나머지로 지정합니다. 두(오프세트 또는 길이) 수 모두 음수이면,
사용한 수는 오프세트 또는 지정한 길이에 추가된 환경 변수 값의
길이입니다.
%PATH:~-10%
은(는) PATH 변수의 마지막 10 문자를 추출합니다.
%PATH:~0,-2%
은(는) PATH 변수의 2 문자만 제외한 모든 문자를 추출합니다.
명령줄에서 help set 을 입력하면 자세한 사용법을 알 수 있다.
@echo off
for /f "delims=" %%i in (list.txt) do call :lbl_echo %%i
goto :eof
:lbl_echo
set element=%*
set start_ch=%element:~0,1%
if "%start_ch%"=="#" (
echo skip : %element%
) else (
echo echo : %element%
)
goto :eof
예를 들어 list.txt 파일을 읽어 라인별로 처리하고 싶은데 첫번째 문자열이 # 이면 무시하고 싶으면 위와 같은 배치파일을 작성할 수 있다. %element:~0,1% 같은 식으로 첫번째 문자열을 가져와 비교해서 처리하면 된다.
use test;
create table if not exists bulkinsert
(
seq_id bigint not null auto_increment primary key,
col_char_1 char(64) COLLATE utf8mb4_bin NOT NULL COMMENT 'col1',
col_bigint_2 bigint NOT NULL COMMENT 'col2',
col_char_3 char(64) COLLATE utf8mb4_bin NOT NULL COMMENT 'col3'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
예를 들어 test db 에 bulkinsert 라는 테이블을 만들고 데이터를 추가해보자.
load data local infile 'D:/test/work/test/bulkinsert.csv' # 경로
replace into table bulkinsert # 테이블명
lines terminated by '\n' # 열 구분자
(col_char_1, col_bigint_2, col_char_3); # 칼럼 목록
추가할 데이터 파일의 절대 경로를 적어주고 대상 테이블, 열 구분자, 칼럼 목록을 적어주면 된다.
Error Code: 2068. LOAD DATA LOCAL INFILE file request rejected due to restrictions on access.
별 문제없이 실행되면 좋겠지만 기본 설정으로 실행하면 위와 같은 오류 메시지가 보일 수 있다.
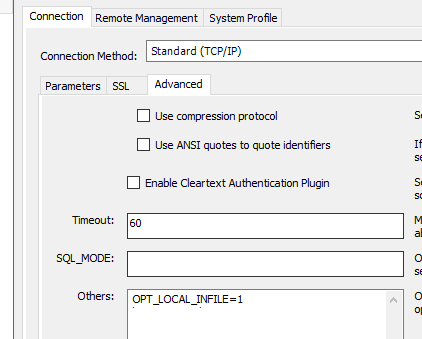
MySQL Workbench 를 사용 중이라면 Edit Connection > Connection > Advanced 에 OPT_LOCAL_INFILE=1 을 추가하자. mysql cli 를 사용 중이라면 --local-infile=1 을 실행 파라미터에 추가하자.
P.S. 내 개발환경에서는 대문자로 해야했다. 테이블 이름 같은 경우 윈도 버전은 대소문자 안가리고 리눅스는 가렸는데 실행 파람은 좀 특이했다.